
Tech Resources I love!
Preparing for technical interviews
Ace Every Stage of Your Next Technical Interview with these curated resources
Courses on Cloud, Data and AI
Step by step courses with hands-on experience and projects
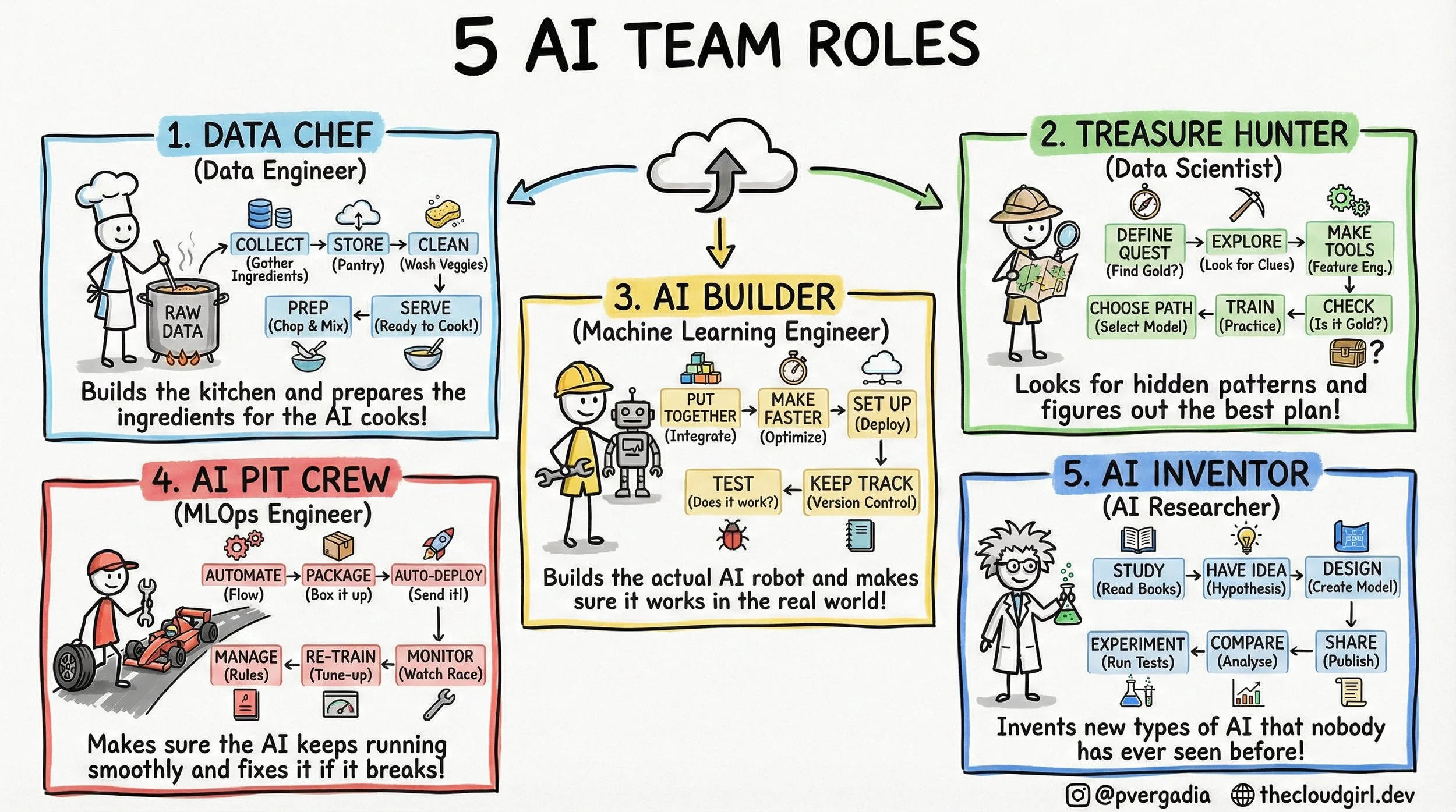
The 5 AI Engineer Team Roles
The 5-Layer AI Team Architecture
If you look at a job board today, you will see a flood of listings for "AI Engineers." But if you look at the architecture of a successful AI product, you rarely see a single "engineer" doing the work. You see a pipeline. You see a distributed system of human capital where context switching is the enemy of progress.
1. The Data Chef (Data Engineering)
In the real world, this is the realm of Spark, Airflow, and Kafka. The technical challenge here is throughput and consistency. The Data Chef isn't worried about "accuracy" in a statistical sense; they are worried about schema drift and data lineage. If the raw data ingestion pipeline has high latency, the real-time inference model downstream starves. They build the "kitchen"—the Data Lakehouse—ensuring that `Raw Data` is transformed into `Feature Store` ready vectors.
2. The Treasure Hunter (Data Science)
This role is often confused with engineering, but the output is fundamentally different. The output of an Engineer is code; the output of a Scientist is insight. They deal in p-values and confidence intervals. The critical step in the sketch is "Make Tools" (Feature Engineering). This is the process of converting domain knowledge into numerical representation. The trade-off here is Exploration vs. Exploitation—how much time do we spend searching for a better model architecture versus shipping the one we have?
3. The AI Builder (Machine Learning Engineer)
This is where the Jupyter Notebook dies and the Microservice is born. The ML Engineer refactors the Data Scientist's experimental code into production-grade Python or C++. They care deeply about inference latency and memory footprints. They ask: "Can this Transformer run on a CPU instance to save costs?" or "How do we quantize this model without losing accuracy?" Their workflow in the sketch—Put Together -> Make Faster -> Set Up—is essentially the containerization and optimization pipeline.
4. The AI Pit Crew (MLOps Engineer)
This is the most undervalued role in early-stage startups. In traditional software, code behaves deterministically. In AI, code depends on data, which changes constantly. This is called Data Drift or Concept Drift. The Pit Crew builds the automated infrastructure that detects when the model's performance drops (Monitor), triggers a new training run (Re-Train), and pushes the new binary to production (Auto-Deploy). If your AI strategy doesn't have a Pit Crew, you don't have a product; you have a ticking time bomb of degradation.
5. The AI Inventor (AI Researcher)
While the Builder uses `from transformers import AutoModel`, the Inventor is reading ArXiv papers to understand the math behind the attention mechanism. They operate on a longer time horizon. Their work involves high failure rates because they are testing unproven hypotheses. They aren't optimizing for latency; they are optimizing for state-of-the-art (SOTA) benchmarks.
When building your team, stop looking for a "Unicorn" who can do all five. You wouldn't hire a plumber to wire your house, even if they both work in construction. Respect the architecture. Respect the specialized tooling required for each stage. Build the kitchen, then hire the cooks.