
What is Context Engineering and Why do we Need it?
Stop searching for the "perfect prompt" and start building the perfect environment.
Introduction: The "Goldfish" Problem
You’ve been there. You’re having a breakthrough conversation with an AI coding assistant. It’s writing perfect Python functions, understanding your variable names, and anticipating your next move. Then, you step away for lunch.
When you come back and ask, "Okay, let's refactor that last part," the magic is gone. The AI looks at you blankly and asks, "Which part?" Or worse, it hallucinates a variable that doesn't exist.
In an instant, your brilliant pair programmer has turned into a goldfish.
This isn't a failure of the model's intelligence; it's a failure of context. We tend to treat AI interactions like a series of isolated text messages, expecting the model to "just know" what we mean. But LLMs are stateless by design. Without a mechanism to retain and organize information, every interaction is Day One.
Most developers try to fix this with Prompt Engineering—tweaking words, adding "please," and writing paragraph-long instructions. But the industry is quietly moving toward a more powerful paradigm: Context Engineering.
Context Engineering isn't about asking better questions. It's about systematically managing the information, history, and tools an AI sees to ensure every response is grounded, relevant, and accurate.
Context Engineering vs. Prompt Engineering
It’s easy to confuse the two, but the difference is architectural.
Prompt Engineering is the "Micro" view. It focuses on optimizing the wording of a single request. Think of it like writing a carefully worded email to a colleague to get a specific task done. You might iterate on the subject line or the tone to get the best result.
Context Engineering is the "Macro" view. It focuses on optimizing the entire environment the model operates in. It’s analogous to onboarding that colleague with a handbook, a project history, access to the right shared drives, and a clear org chart before they even start working.
Why does this matter now? We’ve reached a plateau with model intelligence. Gemini, GPT-4o and Claude 3.5 Sonnet are incredibly smart. The bottleneck is no longer their reasoning ability; it’s the relevance of the information you feed them. An average model with perfect context will outperform a genius model with zero context every time.
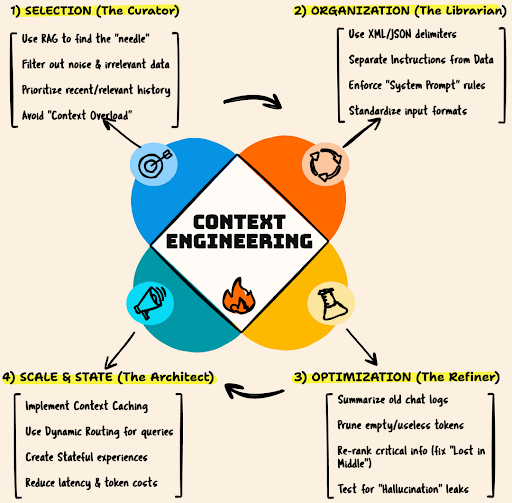
The Core Pillars of Context Engineering
To build a system that "knows" what you're doing, you need to master three technical pillars.
A. Selection (The Curator)
You can't just dump your entire database into the prompt. It’s expensive, slow, and confusing for the model. You must select only the most relevant data.
The Technique: RAG (Retrieval-Augmented Generation). Instead of pasting a 50-page manual, you use semantic search to find the specific "needle in the haystack"—the three paragraphs relevant to the user's current question—and inject only those.
B. Compression (The Summarizer)
Even with massive context windows, "more" isn't always better. Distant, irrelevant details dilute the model's attention.
The Technique: Summarization & Pruning. Instead of feeding the AI 50 pages of raw chat logs, you compress it into a state object: "User is debugging a Python script for a finance app. We tried X and Y, which failed. Current error is Z." This keeps the "signal" high and the "noise" low.
C. Organization (The Librarian)
How you structure data matters as much as the data itself. A wall of text is hard to parse.
The Technique: Structured Delimiters. Use XML tags (like <documents> or <history>) or JSON schemas to clearly separate "System Instructions" from "User Data". This helps the model understand that one part is a rule to follow, and the other is data to process.
Context Engineering
The "Lost in the Middle" Phenomenon (Why You Can't Just Dump Data)
You might ask: "Why do I need to engineer context? Can't I just use Gemini 1.5 Pro with its 2-million token window and upload my whole codebase?"
Technically, yes. Practically, no.
Research has shown a persistent issue called the "Lost in the Middle" phenomenon. LLMs are excellent at retrieving information from the very beginning of a prompt and the very end. But details buried in the middle of a massive context window often get ignored or hallucinated.
Context Engineering isn't just about fitting data into the window; it's about information hierarchy. By using techniques like re-ranking (ordering the most important context last, near the query) and aggressive filtering, you ensure the model actually sees the data you gave it.
Real-World Example: The "Smart" vs. "Dumb" Coding Assistant
Let’s look at a concrete scenario. You ask an AI: "Fix the bug in auth.py."
The "Dumb" (Prompt Engineered) Way: You paste the code of auth.py into the chat.
Result: The AI fixes the syntax error but creates a new problem because it doesn't know that auth.py relies on a custom class in database.py. It hallucinates a standard library solution that breaks your app.
The "Smart" (Context Engineered) Way: You don't paste anything. You just ask the question. Behind the scenes, the Context Engine kicks in:
Retrieval: It sees you mentioned auth.py. It automatically fetches that file and scans the import statements to fetch the referenced database.py.
History: It pulls the error logs from your terminal for the last 5 minutes to see the exact stack trace.
Rules: It injects your team's "Style Guide" rule: "Always use async/await for DB calls."
Result: The AI generates a fix that solves the syntax error, respects the database.py dependencies, and follows your async style guide—all without you manually explaining any of it.
Advanced Techniques: Moving to "Stateful" AI
If you want to be on the cutting edge, here is where the industry is heading.
Context Caching: Re-sending the same massive system prompt or codebase for every single query is wasteful. New features from providers like Anthropic and Google allow you to "cache" huge amounts of context (like your entire documentation) once, and then query it cheaply and quickly. It turns stateless calls into a "stateful" experience.
Dynamic Context Routing: Not every query needs the same context. A "Router" (a small, fast model) analyzes the user's intent first.
Simple question? Route to a basic prompt.
Complex architecture question? Route to a workflow that fetches design docs, architecture diagrams, and ticket history before answering.
Conclusion: Context is King
We are moving past the era of "Prompt Engineering." The future belongs to systems that can autonomously gather, filter, and manage their own context.
If you are a developer, stop obsessing over whether to say "please" or "you are an expert." Start building better data pipelines. Focus on what your model knows, not just what it hears.
Don't just ask better questions. Give your AI better answers.