
How DoorDash Built a Voice AI Contact Center That Actually Works
Picture this: You're a DoorDash driver—a Dasher, as they're called—navigating traffic while trying to find a customer's apartment. Something goes wrong with the app. You need help. Now.
You're not going to pull over and type out a detailed support message. You're going to call.
This is the reality DoorDash faced when they decided to overhaul their customer support. Hundreds of thousands of calls every single day from Dashers, merchants, and customers—many of them needing answers while literally on the move. And when you're driving for a living, every minute on hold is money lost.
So how do you build an AI support system that doesn't feel like talking to a brick wall? That's exactly what DoorDash figured out, and there are some lessons here that anyone building AI applications should pay attention to.
Voice AI Is Harder Than Text
Most companies that implement AI chatbots start with text. Makes sense—it's easier to prototype, easier to debug, and users can wait a few seconds for a response without feeling like something's broken.
Voice is a completely different beast.
When you're on a phone call, even a two-second pause feels awkward. Three seconds? You start wondering if the call dropped. Five seconds? You've already hung up and called back.
DoorDash already had a decent self-service system running on Amazon Connect with Amazon Lex—the kind of "press 1 for account issues, press 2 for payment questions" setup you've probably used a hundred times. It was working. They'd reduced agent transfers by 49% and saved about $3 million a year in operational costs.
But "working" isn't the same as "great." Most calls were still getting routed to human agents. Dashers were spending too much time waiting for help when they needed to be back on the road making deliveries.
The question wasn't whether to use generative AI. The question was: how do you make it fast enough for voice?
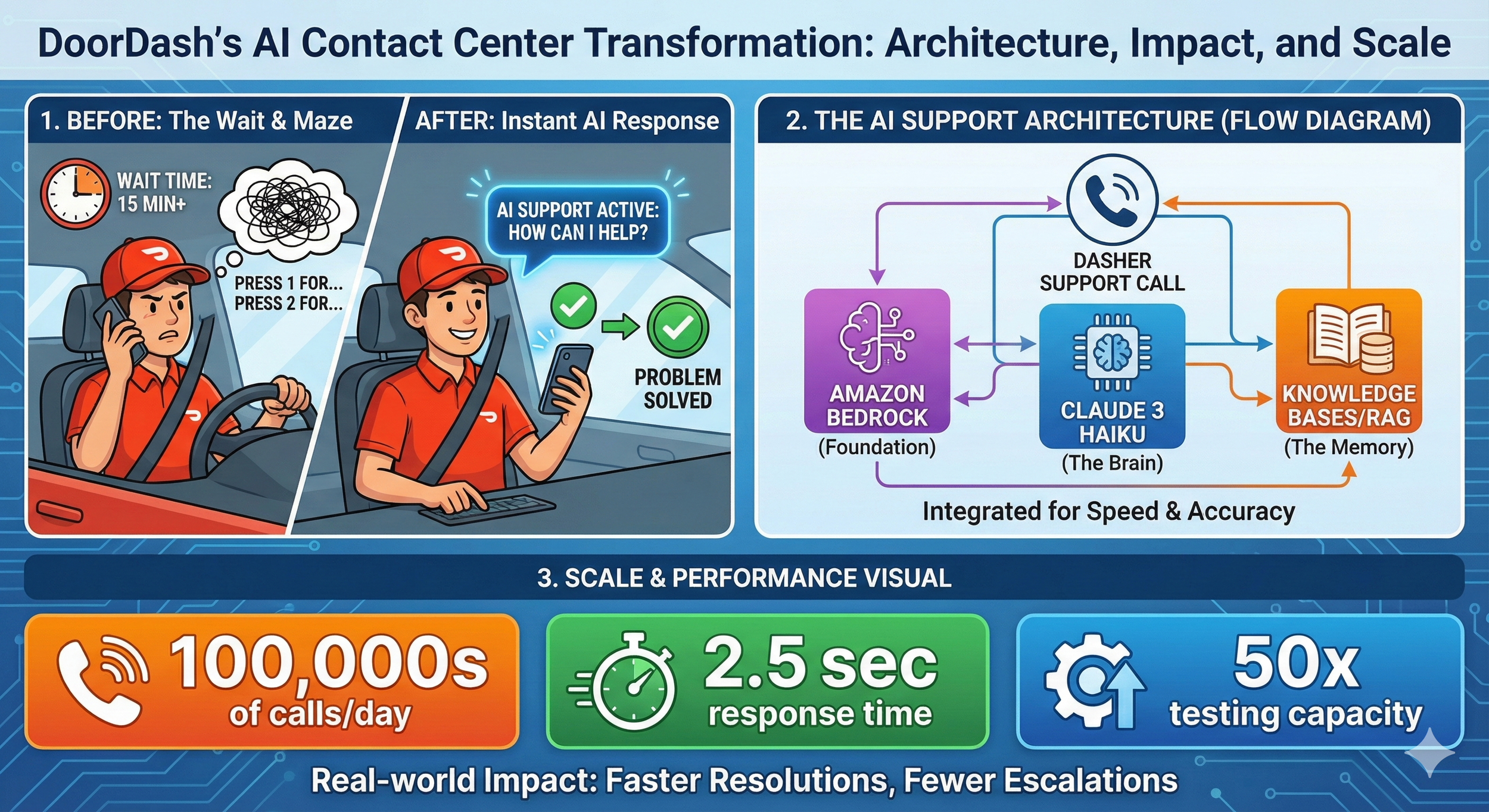
Why Amazon Bedrock?
DoorDash partnered with AWS through their Generative AI Innovation Center—a program where AWS pairs companies with their AI experts to build production-ready solutions. Not a proof of concept. Not a demo. Something that could handle hundreds of thousands of real calls.
They chose Amazon Bedrock as their foundation, and the reasoning is worth understanding.
For beginners: Bedrock is essentially Amazon's "one-stop shop" for accessing large language models. Instead of managing your own infrastructure or figuring out how to deploy models, you get a managed service with multiple AI models available through a single API. Think of it like what AWS did for servers, but for AI models.
For practitioners: The real value here isn't just convenience. Bedrock gives you access to multiple foundation models—including Anthropic's Claude family—without vendor lock-in. You can experiment with different models, swap them out, and fine-tune your approach without rebuilding your entire architecture. DoorDash reported a 50% reduction in development time just from using Bedrock instead of building custom integrations.
For architects: The security story matters here too. Bedrock provides built-in encryption and ensures that customer data stays within your application boundaries. DoorDash explicitly noted that no personally identifiable information gets passed to the generative AI components—the architecture enforces this separation.
Getting the Speed Right with Claude 3 Haiku
Remember that latency issue? This is where model selection becomes critical.
DoorDash tested multiple models and landed on Anthropic's Claude 3 Haiku for their voice application. The result: response latency of 2.5 seconds or less.
Now, 2.5 seconds might sound like a lot if you're used to text chatbots that respond almost instantly. But remember—this isn't just generating a response. The system needs to:
Transcribe the caller's speech to text
Process the request and understand the intent
Search the knowledge base for relevant information
Generate an appropriate response
Convert that response back to speech
All of that in under 2.5 seconds. That's actually impressive.
But Haiku wasn't just chosen for speed. Claude models have specific capabilities around hallucination mitigation, prompt injection detection, and identifying abusive language. When you're building a customer-facing voice system that handles hundreds of thousands of calls daily, you really don't want your AI confidently giving wrong information or being manipulated by bad actors.
The RAG Architecture
Let's get into how this actually works.
DoorDash implemented Retrieval-Augmented Generation (RAG) using Knowledge Bases for Amazon Bedrock. If you're not familiar with RAG, here's the gist:
Instead of asking the AI model to answer questions purely from what it learned during training, you give it access to your company's actual documentation. When a Dasher asks "how do I update my payment information?", the system first searches DoorDash's help center for relevant articles, then feeds that context to Claude along with the question. The model generates an answer based on your actual, up-to-date documentation—not whatever was in its training data.
Why this matters:
Accuracy: The AI can only answer based on your approved content. If your payment process changed last week, you update the help center, and the AI immediately gives the right answer.
Controllability: You're not hoping the model "knows" the right answer. You're ensuring it does.
Auditability: You can trace exactly which documents informed any given response.
Knowledge Bases for Amazon Bedrock handles the messy parts—ingesting documents, creating embeddings, managing the retrieval workflow, and augmenting prompts. DoorDash didn't have to build custom integrations or manage their own vector database. They pointed the system at their help center and let the managed service handle the plumbing.
The Testing Framework That Made It Possible
This part caught my attention and doesn't get talked about enough.
Before this project, DoorDash's contact center team had to pull actual agents off the support queue to manually test new features. They'd have agents call in, go through scenarios, and report back. It was slow, expensive, and couldn't scale.
Working with the AWS team, they built an automated testing framework using Amazon SageMaker. The system can now run thousands of tests per hour—a 50x increase from their previous capacity. More importantly, it doesn't just check if the AI responded; it semantically evaluates whether responses are actually correct compared to ground-truth answers.
This is the kind of infrastructure investment that separates companies that successfully deploy AI from those that launch something broken and never recover user trust.
For teams building similar systems: Don't underestimate testing. Your AI might work perfectly in demos but fail spectacularly on edge cases. Build evaluation frameworks early. Test at scale. Have a way to measure quality beyond "did it respond?"
The Results
Let's look at the numbers DoorDash shared:
Hundreds of thousands of calls per day handled by the generative AI solution
Thousands fewer escalations to live agents daily
Fewer agent tasks required to resolve support inquiries
8 weeks from kickoff to live A/B testing
Those are real, material improvements. The solution rolled out to all Dashers in early 2024 and has been running in production since.
What I find more interesting is what they're planning next.
DoorDash mentioned they're working on expanding the knowledge bases (more topics the AI can handle) and integrating with their "event-driven logistics workflow service." Translation: the AI won't just answer questions; it'll take actions on behalf of users.
Imagine calling support and instead of just hearing "you can update your payment method in settings," the AI says "I've updated your payment method to the new card. You should see it reflected now."
That's a fundamentally different product. And it's where this technology is heading.
Takeaways
Whether you're building AI applications, evaluating vendors, or just trying to understand where this technology is going, a few things stand out:
Model selection is architecture. Choosing Claude 3 Haiku wasn't just about speed—it was about the full package of latency, accuracy, safety features, and cost. Different use cases need different models.
RAG isn't optional for enterprise. If you're building customer-facing AI that needs to give accurate, current information, you need retrieval-augmented generation. Relying purely on model training data is asking for trouble.
Voice AI is harder than text AI. The latency requirements alone change everything. If you're thinking about voice applications, budget more time and expect different trade-offs.
Testing infrastructure pays dividends. DoorDash's investment in automated evaluation let them iterate faster and deploy with confidence. This is table stakes for production AI.
Managed services accelerate deployment. A 50% reduction in development time is significant. Sometimes the right move is to pay for infrastructure that lets you focus on your actual product.
Where This Is All Heading
There's a pattern emerging in how successful companies deploy generative AI: they start with high-volume, repetitive tasks where the cost of errors is manageable and the improvement potential is obvious.
Customer support checks all those boxes. Hundreds of thousands of daily interactions. Many questions are routine ("how do I...?"). The existing baseline (hold music) is so bad that even imperfect AI feels like an improvement. And humans remain in the loop for complex issues.
DoorDash didn't try to replace their entire support operation with AI. They augmented it. The generative AI handles the straightforward stuff, which frees up human agents to focus on complex problems that actually need human judgment.
That's not the flashiest vision of AI, but it might be the most realistic one. Incremental improvements that compound. Real cost savings that fund further development. Gradual expansion of capabilities as the technology matures.
Not every AI story needs to be revolutionary. Sometimes, "it works, it saves money, and customers like it better" is exactly the story worth telling.