
Tech Resources I love!
Preparing for technical interviews
Ace Every Stage of Your Next Technical Interview with these curated resources
Courses on Cloud, Data and AI
Step by step courses with hands-on experience and projects
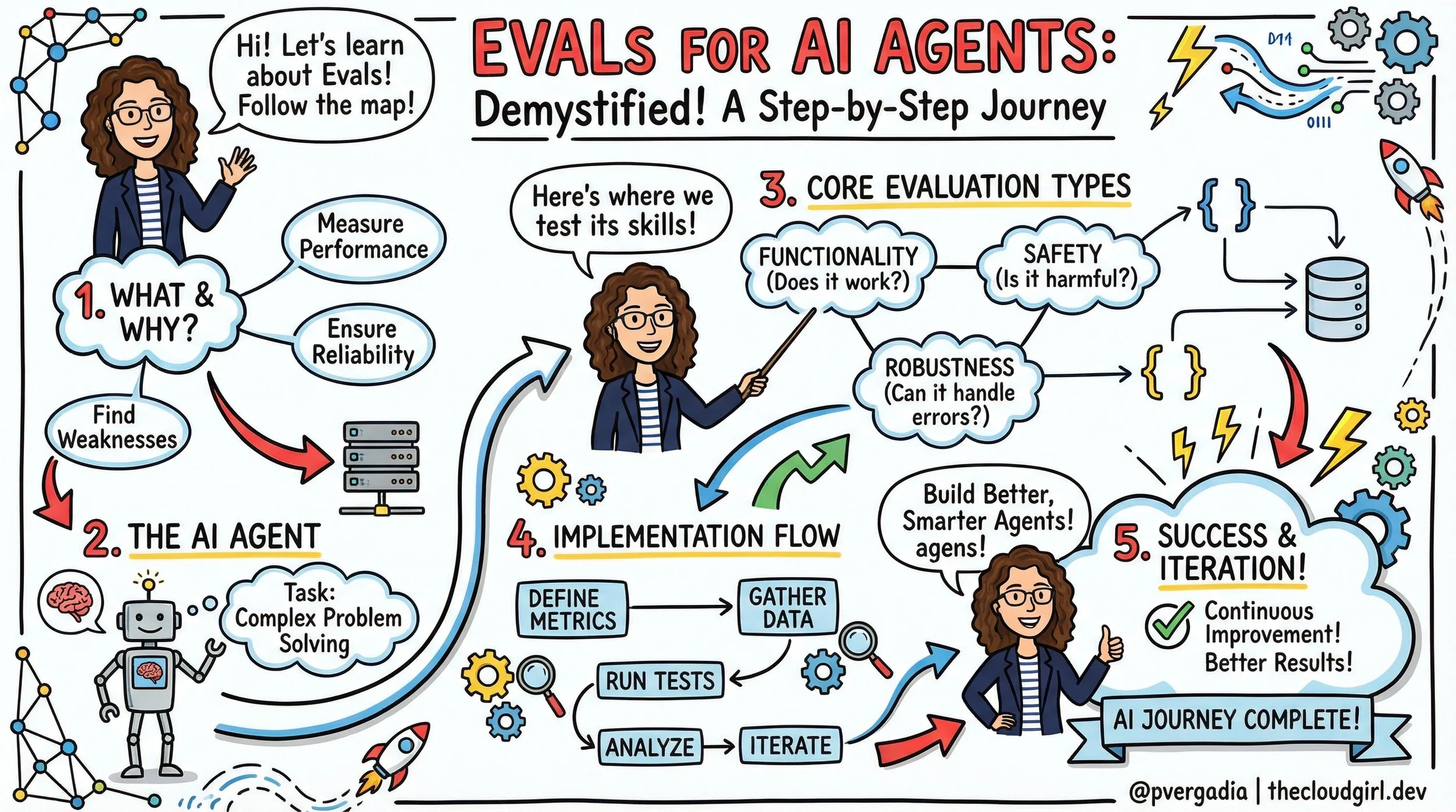
Demystifying Evals: How to Test AI Agents Like a Pro
Demystifying Evals: How to Test AI Agents Like a Pro
Written By Priyanka Vergadia
If you’ve moved from building simple RAG pipelines to autonomous AI agents, you’ve likely hit a wall: evaluation.
With a standard LLM call, you have a prompt and a response. It’s easy to grade. But an agent operates over multiple turns, calls tools, modifies environments, and corrects its own errors. How do you test a system that is non-deterministic and whose "answer" isn't just text, but a side effect in a database or a file system?
Anthropic recently shared their internal playbook on agent evaluation. Here is the developer’s guide to building rigorous, scalable evals for AI agents.
The Flying Blind Problem
When you first build an agent, you probably test it manually ("vibes-based" testing). This works for prototypes but breaks at scale. Without automated evals, you are flying blind. You can't distinguish real regressions from noise, and you can't confidently swap in a new model (like moving from Claude 3.5 Sonnet to a newer version) without weeks of manual re-testing.
The Golden Rule: Start building evals early. They force you to define what "success" actually looks like for your product.
IMAGE
The Anatomy of an Agent Eval
An agent evaluation is more complex than a standard unit test. It generally consists of seven key components:
The Task: The specific scenario or test case (e.g., "Fix this GitHub issue").
The Harness: The infrastructure that sets up the environment and runs the agent loop.
The Agent Loop: The model interacting with tools, reasoning, and the environment.
The Transcript: The full log of tool calls, thoughts, and outputs.
The Outcome: The final state of the environment (e.g., Is the file edited? Is the row in the DB?).
The Grader: The logic that scores the transcript or the outcome.
The Suite: A collection of tasks grouped by capability (e.g., "Refund Handling" suite).
3 Strategies for Grading Agents
You cannot rely on just one type of grader. A robust system uses a "Swiss Army Knife" approach:
1. Code-Based Graders (The "Unit Test")
These are fast, cheap, and deterministic.
Best for: Verifying outcomes.
Examples: Regex matching, static analysis (linting generated code), checking if a file exists, running a unit test against generated code.
Pros: Zero hallucinations, instant feedback.
Cons: Can be brittle; misses nuance.
2. Model-Based Graders (LLM-as-a-Judge)
Using an LLM to grade another LLM.
Best for: Assessing soft skills or reasoning.
Examples: "Did the agent adopt a polite tone?", "Did the agent logically deduce the error before fixing it?"
Pros: flexible; handles open-ended output.
Cons: Non-deterministic; can be expensive; requires calibration.
3. Human Graders (The Gold Standard)
Best for: Calibrating your Model-Based graders and final QA.
Strategy: Use humans to grade a subset of logs, then tune your LLM judge to match the human scores.
Architecting Evals by Agent Type
Different agents require different evaluation architectures.
For Coding Agents
Coding agents are actually the "easiest" to evaluate because code is functional.
The Setup: Give the agent a broken codebase or a feature request.
The Check: Run the actual test suite. If the tests pass, the agent succeeded.
Advanced: Use Transcript Analysis to check how it solved it. Did it burn 50 turns trying to guess a library version? Did it delete a critical config file? (Use an LLM grader to review the diff).
For Browser/GUI Agents
These are tricky because the output is actions on a screen.
Token Efficiency vs. Latency: Extracting the full DOM is accurate but token-heavy. Screenshots are token-efficient but slow.
The Check: Don't just check the final URL. Check the backend state. If the agent "bought a laptop," check the mock database to see if the order exists.
Handling Non-Determinism (pass@k)
Agents are stochastic. Running a test once isn't enough. Anthropic recommends borrowing metrics from code generation research:
pass@1: Did the agent succeed on the first try? (Critical for cost-sensitive tasks).
pass@k: If we run the agent $k$ times (e.g., 10 times), what is the probability at least one run succeeds?
pass^k: The probability that all $k$ trials succeed. (Use this for regression testing where consistency is paramount).
The Developer's Checklist: How to Start
If you have zero evals today, follow this progression:
Start with "Capability Evals": Pick 5 tasks your agent fails at. Write evals for them. This is your "hill to climb."
Add "Regression Evals": Pick 5 tasks your agent succeeds at. Write evals to ensure you never break them.
Read the Transcripts: Don't just look at the PASS/FAIL boolean. Read the logs. If an agent failed, was the instructions unclear? Did the grader hallucinate?
Watch for Saturation: If your agent hits 100% on a suite, that suite is no longer helping you improve capabilities. It has graduated to a pure regression test. You need harder tasks.
Tooling
You don't always need to build from scratch. The ecosystem is maturing:
Harbor: Good for containerized/sandbox environments.
Promptfoo: Excellent for declarative, YAML-based testing.
LangSmith / Braintrust: Great for tracing and online evaluation.
Building agents without evals is like writing code without a compiler. You might feel like you're moving fast, but you'll spend twice as long debugging in production. Start small, verify outcomes, and automate the loop.
Priyanka Vergadiahttps://thecloudgirl.dev
The 5 AI Engineer Team Roles
EDIT SITE FOOTER
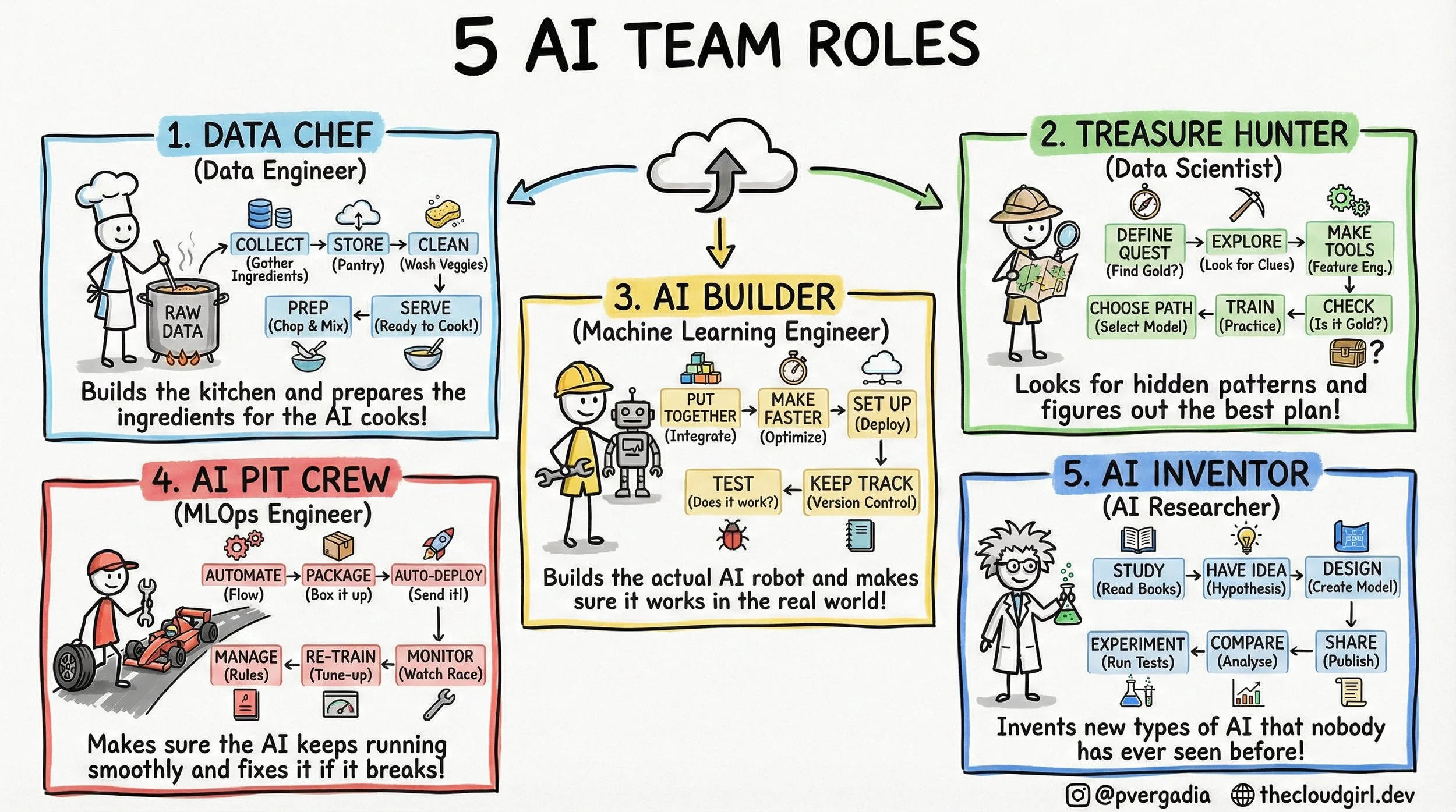
The 5 AI Engineer Team Roles
The 5-Layer AI Team Architecture
If you look at a job board today, you will see a flood of listings for "AI Engineers." But if you look at the architecture of a successful AI product, you rarely see a single "engineer" doing the work. You see a pipeline. You see a distributed system of human capital where context switching is the enemy of progress.
1. The Data Chef (Data Engineering)
In the real world, this is the realm of Spark, Airflow, and Kafka. The technical challenge here is throughput and consistency. The Data Chef isn't worried about "accuracy" in a statistical sense; they are worried about schema drift and data lineage. If the raw data ingestion pipeline has high latency, the real-time inference model downstream starves. They build the "kitchen"—the Data Lakehouse—ensuring that `Raw Data` is transformed into `Feature Store` ready vectors.
2. The Treasure Hunter (Data Science)
This role is often confused with engineering, but the output is fundamentally different. The output of an Engineer is code; the output of a Scientist is insight. They deal in p-values and confidence intervals. The critical step in the sketch is "Make Tools" (Feature Engineering). This is the process of converting domain knowledge into numerical representation. The trade-off here is Exploration vs. Exploitation—how much time do we spend searching for a better model architecture versus shipping the one we have?
3. The AI Builder (Machine Learning Engineer)
This is where the Jupyter Notebook dies and the Microservice is born. The ML Engineer refactors the Data Scientist's experimental code into production-grade Python or C++. They care deeply about inference latency and memory footprints. They ask: "Can this Transformer run on a CPU instance to save costs?" or "How do we quantize this model without losing accuracy?" Their workflow in the sketch—Put Together -> Make Faster -> Set Up—is essentially the containerization and optimization pipeline.
4. The AI Pit Crew (MLOps Engineer)
This is the most undervalued role in early-stage startups. In traditional software, code behaves deterministically. In AI, code depends on data, which changes constantly. This is called Data Drift or Concept Drift. The Pit Crew builds the automated infrastructure that detects when the model's performance drops (Monitor), triggers a new training run (Re-Train), and pushes the new binary to production (Auto-Deploy). If your AI strategy doesn't have a Pit Crew, you don't have a product; you have a ticking time bomb of degradation.
5. The AI Inventor (AI Researcher)
While the Builder uses `from transformers import AutoModel`, the Inventor is reading ArXiv papers to understand the math behind the attention mechanism. They operate on a longer time horizon. Their work involves high failure rates because they are testing unproven hypotheses. They aren't optimizing for latency; they are optimizing for state-of-the-art (SOTA) benchmarks.
When building your team, stop looking for a "Unicorn" who can do all five. You wouldn't hire a plumber to wire your house, even if they both work in construction. Respect the architecture. Respect the specialized tooling required for each stage. Build the kitchen, then hire the cooks.