
The Life of an AI Query: Inside ChatGPT, Gemini, & Claude
When you type a prompt into ChatGPT, Gemini, or Claude, the response feels instantaneous. It feels like magic. But behind that blinking cursor lies a massive symphony of distributed systems, high-bandwidth memory, and high-dimensional mathematics.
For developers and engineers, "How does it work?" isn't just a curiosity—it is a system design question.
In this post, we will trace the millisecond-by-millisecond journey of a single request, from the moment you hit "Enter" to the final generated token. We will use a specific prompt to illustrate how the model reasons:
User Prompt: "Write a haiku about a robot loving a cat."
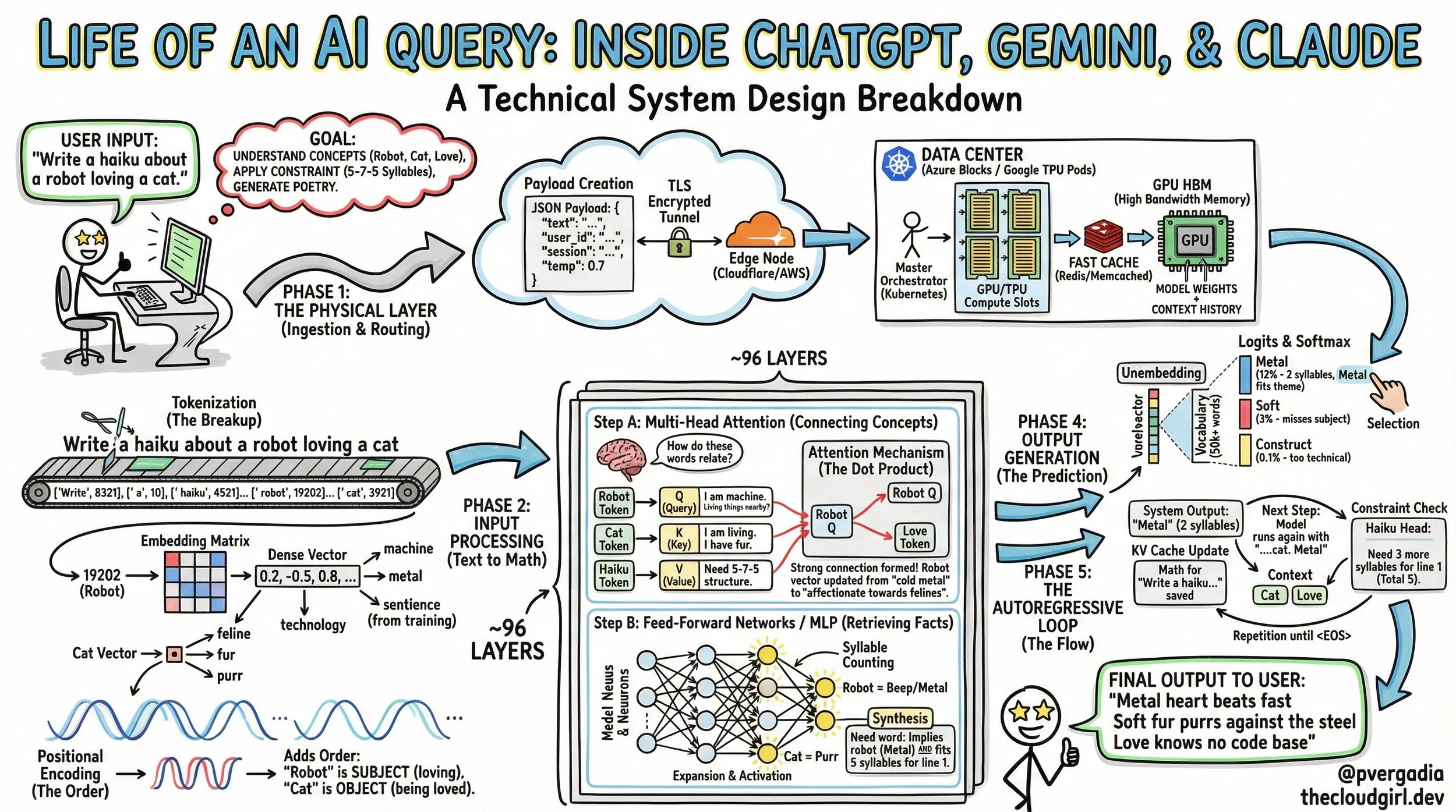
Phase 1: The Physical Layer (Ingestion & Routing)
The Travel
Before the math begins, the logistics must be handled. When you submit your prompt, it is wrapped in a JSON payload along with metadata (your user ID, session history, and temperature settings).
The Handshake: Your request travels via TLS encryption, hitting an edge node (like Cloudflare) before routing to the nearest inference cluster (e.g., an Azure block for OpenAI or a TPU Pod for Google).
Orchestration: A load balancer directs your query to a specific GPU/TPU with available compute slots.
VRAM Loading: The model is too large to load on the fly. The weights (hundreds of gigabytes) are permanently resident in the GPU's High Bandwidth Memory (HBM). Your specific prompt and chat history are loaded into the active memory stack.
Phase 2: Input Processing (Text to Math)
The Translation
The GPU cannot understand the string "Robot." It only understands numbers.
1. Tokenization (The Breakup)
The raw text is sliced into sub-word units called tokens.
Input: ["Write", " a", " haiku", " ...", " robot", " loving", " a", " cat"]
IDs: [8321, 10, 4521, ..., 19202, 8821, 10, 3921]
Note that the concept of a "Robot" has been converted into the integer 19202.
2. Embedding (The Meaning)
The integer 19202 is used to look up a specific address in the model's Embedding Matrix. It retrieves a dense vector—a list of thousands of floating-point numbers.
The Robot Vector: Contains mathematical values that align it with concepts like "metal," "machine," and "technology," but also "sentience" (derived from training data).
The Cat Vector: Aligns with "biological," "fur," and "pet."
3. Positional Encoding (The Order)
Transformers process all words simultaneously (in parallel). Without help, the model wouldn't know if the Robot loves the Cat or the Cat loves the Robot.
The Fix: A sinusoidal wave pattern (Positional Encoding) is added to the vectors. This stamps the "Robot" vector with the mathematical signature of being the subject (Position 6) and the "Cat" as the object (Position 9).
Phase 3: The Transformer Block (The Reasoning Engine)
The Deep Dive
The signal now travels through roughly 96 stacked layers of the Transformer. In each layer, the vectors are refined through two distinct mechanisms.
Step A: Multi-Head Self-Attention (The Context Engine)
This is the heart of the Transformer. The model asks: "How do these words relate to each other?"
It does this using three learned matrices: Query (Q), Key (K), and Value (V).
The Interaction:
The "Robot" token generates a Query: "I am a machine. Are there any living things nearby?"
The "Cat" token generates a Key: "I am a living thing. I have fur."
The "Haiku" token generates a Key: "I impose a 5-7-5 syllable constraint."
The Attention Score:
The model calculates the Dot Product of the Robot's Query and the Cat's Key.
Result: A high score. The model now "pays attention" to the relationship between the machine and the animal.
Simultaneously, the "Haiku" token lights up, signaling that brevity is required.
Step B: The MLP (The Knowledge Bank)
After Attention, the data passes through a Feed-Forward Network (Multi-Layer Perceptron). This is where facts are retrieved.
Activation: The vector is projected into higher dimensions. Specific neurons fire.
The Retrieval: Neurons associated with "counting syllables" activate. Neurons linking "Robots" to "Steel" and "Cats" to "Purring" activate.
Synthesis: The vector for "Robot" is updated. It is no longer just "19202"; it is now a rich data point representing "A metal entity feeling affection for a feline, constrained by a poetic format."
Phase 4: Output Generation (The Prediction)
After passing through all layers, the model arrives at the final vector. It is now time to speak.
Unembedding: The final vector is projected against the model's entire vocabulary (50,000+ words).
The Softmax: The model assigns a probability percentage to every possible next word.
"Metal": 12% (Fits the robot theme, 2 syllables).
"Soft": 3% (Fits the cat theme, but ignores the subject).
"Construct": 0.1% (Too technical/cold).
The Selection: Using a decoding strategy (like Temperature), the model samples the winner: "Metal".
Phase 5: The Autoregressive Loop (The Flow)
The Grind
The model has generated one word. Now the cycle repeats, but with an optimization crucial for system performance.
KV Cache: Instead of recalculating the math for "Write a haiku about a robot...", the model retrieves the calculated Key and Value vectors from the GPU's KV Cache.
The Next Step: It only computes the math for the new token: Metal.
Context Check: It looks at "Cat" and "Haiku".
Constraint: We have 2 syllables (Met-al). We need 3 more to finish the first line (5 total).
Prediction: heart (1 syllable).
The Stream: This loop runs until the standard 5-7-5 structure is complete and an <EOS> (End of Sequence) token is produced.
The Final Output
Metal heart beats fast
Soft fur purrs against the steel
Love knows no code base
Summary
What looks like a simple text response is actually a massive pipeline of data.
Ingestion: Getting the data to the GPU.
Tokenization: Converting language to integers.
Attention: Understanding context and relationships
MLP: Retrieving factual knowledge.
Autoregression: Predicting the future, one token at a time.
Every time you see that cursor blink, you are witnessing a traversal through high-dimensional space, constrained by the speed of light in fiber optic cables and the memory bandwidth of silicon.