
What is GraphRAG: Cheatsheet
Unpacking GraphRAG: Elevating LLM Accuracy and Explainability with Knowledge Graphs
We've all been there. You're building an intelligent agent, leveraging the power of Large Language Models (LLMs) for Q&A, content generation, or customer support. You've implemented Retrieval-Augmented Generation (RAG) – a solid architectural pattern that grounds your LLM in your own data, mitigating hallucinations and improving relevance. Yet, a persistent frustration remains: the LLM struggles with nuanced, multi-hop questions, fails to connect disparate facts, or sometimes, still confidently fabricates details when the answer isn't explicitly stated in a retrieved chunk. The black box problem persists, making it hard to trust the output.
This is precisely the pain point that GraphRAG aims to solve, pushing the boundaries of what's possible with enterprise-grade LLM applications. It's not just an incremental improvement; it's a fundamental shift in how we augment LLMs, moving beyond flat document chunks to leverage the rich, interconnected world of knowledge graphs.
Walkthrough of GraphRAG
If you look at the brilliant sketchnote above, it lays out the GraphRAG paradigm with remarkable clarity. Let's walk through its technical architecture step-by-step, much like we'd discuss a system design over coffee.
What is GraphRAG? At its core, GraphRAG is Retrieval-Augmented Generation powered by Knowledge Graphs. While standard RAG fetches relevant documents or text chunks, GraphRAG specifically uses structured graphs to unearth facts and their intricate relationships. It's about moving from understanding individual sentences to comprehending the entire tapestry of information.
How does GraphRAG Work?
The process flow, as depicted under "HOW IT WORKS & TECHNICAL ARCHITECTURE," unfolds in three crucial stages:
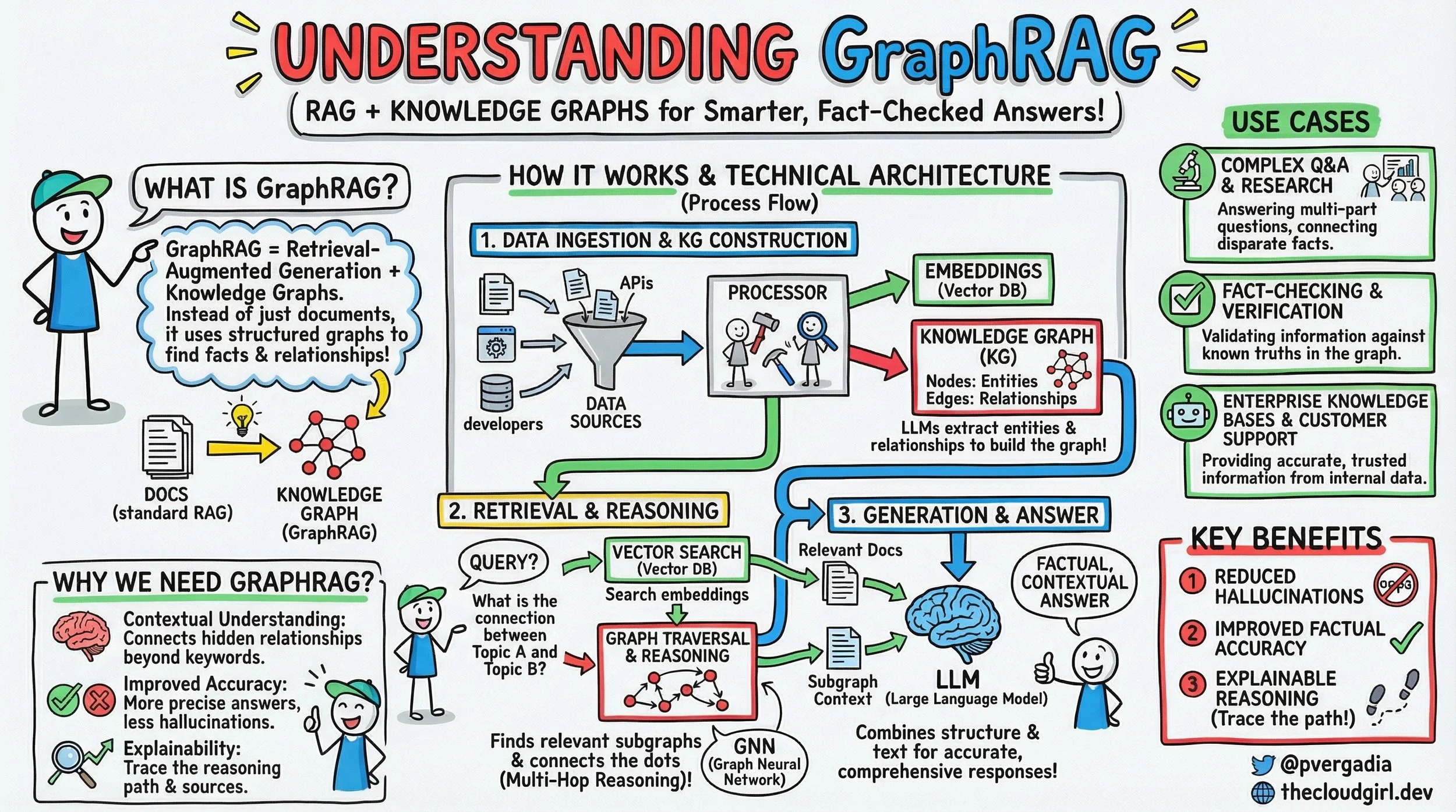
1. Data Ingestion & KG Construction
This is where the magic of structuring your data begins.
Data Sources: We start with diverse data – anything from unstructured documents (PDFs, internal wikis), structured databases, REST APIs, or even human input.
The Processor: Here's a key component. This module takes all that raw, disparate data and orchestrates its transformation. It performs two critical tasks in parallel:
Embeddings (Vector DB): Like standard RAG, chunks of your raw text are embedded into numerical vectors and stored in a Vector Database (e.g., Pinecone, Weaviate, Faiss). This enables semantic search later.
Knowledge Graph (KG) Construction: This is the GraphRAG differentiator. The processor, often leveraging Large Language Models (LLMs) themselves for Information Extraction (IE), extracts entities (nodes) and their relationships (edges) from the raw data. Think of it as an automated Subject-Predicate-Object triple extractor. For instance, from "Priyanka built GraphRAG in 2023," it might extract (Priyanka, built, GraphRAG) and (GraphRAG, year, 2023). This structured data is then stored in a dedicated Graph Database (e.g., Neo4j, Amazon Neptune, ArangoDB). LLMs are incredibly adept at this task, especially when fine-tuned or carefully prompted for Named Entity Recognition (NER) and Relation Extraction (RE).
2. Retrieval & Reasoning
Once your KG is built, the system is ready to answer complex queries:
Query: A user asks a question, potentially one requiring deeper insight than a simple keyword match (e.g., "What is the connection between Topic A and Topic B?").
Vector Search (Vector DB): Just like in standard RAG, an initial semantic search is performed against the vector database to retrieve relevant documents or text snippets that are semantically similar to the query. This provides immediate textual context.
Graph Traversal & Reasoning: This is where GraphRAG truly shines. The query is also processed against the Knowledge Graph. Using Graph Neural Networks (GNNs) or traditional graph traversal algorithms (like BFS, DFS, shortest path), the system explores the graph to find relevant subgraphs, identify multi-hop relationships, and "connect the dots" that might be implicitly spread across multiple documents. A GNN can learn complex patterns and infer relationships that simple traversal might miss, providing a richer "subgraph context."
3. Generation & Answer
The final step brings everything together:
LLM (Large Language Model): The LLM receives two powerful streams of context:
Relevant Docs: The raw text snippets retrieved from the vector database.
Subgraph Context: The structured, inferred relationships and facts from the knowledge graph.
Synthesis: The LLM combines this structural and textual information. Instead of just paraphrasing retrieved text, it can now generate a more accurate, comprehensive, and factual contextual answer by weaving together direct textual evidence with the inferred relational insights from the graph. The outcome is a more reliable and insightful response.
Under the Hood: GraphRAG
Implementing GraphRAG involves several key architectural considerations:
KG Schema Design: Crucial for success. A well-defined ontology (schema for nodes and relationships) is vital for consistent and effective extraction. This requires upfront data modeling expertise.
IE Pipelines: LLMs for NER/RE are powerful but resource-intensive. For high-volume ingestion, a robust pipeline is needed, potentially involving specialized NLP models (e.g., spaCy) for initial extraction, followed by LLMs for more complex, context-dependent relationship identification, or using few-shot/zero-shot prompting.
Graph Database Choice: Considerations include scalability (handling billions of nodes/edges), query performance for complex traversals, and integration with GNN frameworks (e.g., PyTorch Geometric, DGL). Neo4j's Cypher query language is popular for its expressiveness in graph traversal.
Vector Database Integration: Efficient indexing (e.g., HNSW for approximate nearest neighbor search) and low-latency retrieval are paramount.
GNNs for Reasoning: For truly advanced multi-hop reasoning, GNNs can learn embeddings of graph nodes and edges, enabling more sophisticated pattern matching and inference beyond simple pathfinding. Training and deploying GNNs adds complexity but can unlock deeper insights.
Prompt Engineering: Combining disparate contexts (raw text vs. graph facts) effectively within the LLM's prompt is an art. Strategies include explicit formatting of graph triples or subgraphs in the prompt to guide the LLM's reasoning.
Scalability & Latency: KG construction is often a batch process; keeping it updated requires robust data pipelines (e.g., Apache Kafka for event streaming, Spark for batch processing). Real-time inference needs optimized graph queries and GNN inference.
When and Why to Choose GraphRAG
GraphRAG isn't a silver bullet for every LLM use case. It introduces complexity and operational overhead, but the benefits for specific scenarios are transformative.
When to Use GraphRAG:
High Demand for Factual Accuracy & Explainability: When reducing LLM hallucinations and providing verifiable sources is non-negotiable (e.g., legal discovery, medical diagnosis support, financial reporting). The graph provides an auditable trail of facts.
Complex Domains Requiring Multi-Hop Reasoning: When answers depend on connecting facts that aren't adjacent in source documents (e.g., "What is the causal link between X and Y based on our research papers?").
Data with Inherent Relational Structure: If your data naturally has entities and relationships (e.g., supply chains, organizational charts, knowledge bases), GraphRAG leverages this structure optimally.
Enterprise Knowledge Bases: For organizations seeking a single source of truth from internal documents, GraphRAG can power highly accurate and trusted information retrieval for customer support, internal tools, and research.
When NOT to Use GraphRAG:
Simple Q&A Tasks: For straightforward information retrieval where keyword or vector search in raw documents is sufficient, the overhead of KG construction and maintenance is unwarranted.
Small Datasets: If your corpus is small and lacks complex interconnections, the benefits of a KG might not justify the effort.
Highly Dynamic Data with Low Ingestion Latency Tolerance: KG construction and updates can be time-consuming. If your data changes minute-by-minute and real-time reflection in the KG is critical, the pipeline needs significant engineering.
Limited Budget: Graph databases, GNN infrastructure, and LLM API calls for extraction can increase operational costs.
Alternatives:
Standard RAG: Simpler, faster to implement, and often sufficient for many use cases.
Fine-tuning LLMs: Can improve domain-specific performance but is costly, less adaptable to new data without retraining, and doesn't inherently solve the hallucination or explainability problem as well as grounding in a verifiable graph.
Hybrid Search: Combining keyword and vector search offers improved retrieval but lacks the explicit relational reasoning capabilities of a graph.
GraphRAG represents a powerful evolution in augmenting LLMs. By explicitly modeling relationships, we empower LLMs to reason, verify, and explain their answers, moving us closer to truly intelligent and trustworthy AI systems.